The recent publication “Health system-scale language models as all-purpose prediction engines” by Jiang et al. in Nature (June 7th, 2023) piqued my interest. The authors executed an impressive feat by developing a Large Language Model (LLM) that was fine-tuned using data from multiple hospitals within their healthcare system. The LLM’s predictive accuracy was noteworthy, yet it also highlighted the critical limitations of machine learning approaches for prediction tasks using electronic health records (EHRs).
Take a look at the above diagram from our 2021 publication Machine learning for patient risk stratification: standing on, or looking over, the shoulders of clinicians?. It makes the point that the EHR is not merely a repository of objective measurements, but it also includes a record (whether explicit or not) of physician beliefs about the patient’s physiological state and prognosis for every clinical decision recorded. To draw a comparison, using clinicians’ decisions to diagnose and predict outcomes resembles a diligent, well-read medical student who’s yet to master reliable diagnosis. Just as such a student would glean insight from the actions of their supervising physician (ordering a CT scan or ECG, for instance), these models also learn from clinicians’ decisions. Nonetheless, if they were to be left to their own devices, they would be at sea without the cue of the expert decision-maker. In our study we showed that relying solely on physician decisions—as represented by charge details—to construct a predictive model resulted in performances remarkably similar to those models using comprehensive EHR data..
The LLMs from Jiang et al.’s study resemble the aforementioned diligent but inexperienced medical student. For instance, they used the discharge summary to predict readmission within 30 days in a prospective study. These summaries outline the patients’ clinical course, treatments undertaken, and occasionally, risk assessments from the discharging physician. The high accuracy of the LLMs—particularly when contrasted with baselines like APACHE2, which primarily rely on physiological measurements—reveals that the effective use of the clinicians’ medical judgments is the key to their performance.
This finding raises the question: what are the implications for EHR-tuned LLMs beyond the proposed study? It suggests that quality assessment and improvement teams, as well as administrators, should consider employing LLMs as a tool for gauging their healthcare systems’ performance. However, if new clinicians—whose documented decisions might not be as high-quality—are introduced, or if the LLM is transferred to a different healthcare system with other clinicians, the predictive accuracy may suffer. That is because clinician performance is highly variable over time and location. This variability (aka data set shift) might explain the fluctuations in predictive accuracy the authors observed during different months of the year.
Jiang et al.’s study illustrates that LLMs can leverage clinician behavior and patient findings—as documented in EHRs—to predict a defined set of near-term future patient trajectories. This observation paradoxically implies that in the near future, one of the most critical factors for improving AI in clinical settings is ensuring our clinicians are well-trained and thoroughly understand the patients under their care. Additionally, they must be consistent in communicating their decisions and insights. Only under these conditions will LLMs obtain the per-patient clinical context necessary to replicate the promising results of this study more broadly.
6 Topics contained in tweets about COVID-19 in 2020
My daughter has pointed out to me that I spend too much time on Twitter and to emphasize the point she bought me a Twitter addict mug. She urged me to keep to science and big ideas rather than science gossip. Rather than argue that she is unfairly characterizing the way I keep up with developments in the world of science and medicine, I decided that the best defense would be to turn to analyzing tweets and make my Twitter habit a programming project. As my timeline was filled up with tweets about COVID-19, I’ve decided to focus on tweets about the disease and virus. This has afforded me the opportunity to brush up on the Tidyverse and start to sharpen my data science tools for this remarkable, surely biased and yet highly informative stream of messages from around the world about this pandemic, now rounding out its 1st year. This is only part 1. I left the other parts on the cutting floor so that I could quickly check to see if my prior expectations about content were correct (spoiler: there were not).
This hyperlink will bring you to an HTML file with the first version of the Part 1 analysis. I’ll be providing additional versions as I find time to steal from research, teaching and research supervision. Suggestions on presentation or analyses are much appreciated. Comments and critique are welcome too.
Imagine a spectacularly accurate machine learning (ML) algorithm for medicine. One that has been grown and fed with the finest of high quality clinical data, culled and collated from the most storied and diverse clinical sites across the country. It can make diagnoses and prognoses even Dr. House would miss.
Then the covid19 pandemic happens. All of a sudden, prognostic accuracy collapses. What starts as a cough ends up as Acute Respiratory Distress Syndrome (ARDS) at rates not seen in the last decade of training data. The treatments that worked best for ARDS with influenza don’t work nearly as well. Medications such as dexamethasone that have been shown not to help patients with ARDS prove remarkably effective. Patients suffer and the ML algorithm appears unhelpful. Perhaps this is overly harsh. After all, this is not just a different context from the original training data (i..e “dataset shift”), it’s a different causal mechanism of disease. Also, unlike some emergent diseases which present with unusual constellations of findings—like AIDS—coivd19 looks like a lot of common inconsequential infections often until the patient is sick enough to be admitted to a hospital. Furthermore, human clinicians were hardly doing better in March of 2020. Does that mean that if we use ML in the clinic, then clinicians cannot decrease alertness for anomalous patient trajectories? Such anomalies are not uncommon but rather a property of the way medical care changes all the time. New medications are introduced every year with novel mechanisms of action which introduce new outcomes which can be discontinuous as compared to prior therapies and also novel associations of adverse events. Similarly new devices create new biophysical clinical trajectories with new feature sets.
These challenges are not foreign to the current ML literature. There are scores of frameworks for anomaly detection1, for model switching 2, for feature evolvable streaming learning3. They are also not new to the AI literature. Many of these problems were encountered in symbolic AI and were closely related to the Frame Problem that bedeviled AI researchers in the 1970s and 1980s. I’ve pointed this out with my colleague Kun-Hsing Yu4 and discussed some of the urgent measures we must take to ensure patient safety. Many of these are obvious such as clinician review of cases with atypical features of feature distributions, calibration with human feedback and repeated prospective trials. These stopgap measures do not however address the underlying brittleness that will and should decrease trust in the performance of AI programs in clinical care. So although these challenges are not foreign , there is an exciting and urgent opportunity for researchers in ML to address them in the clinical context especially because there is a severe data penury relative to our other ML application domains. I look forward to discussions on these issues in our future ML+clinical meetings (including our SAIL gathering).
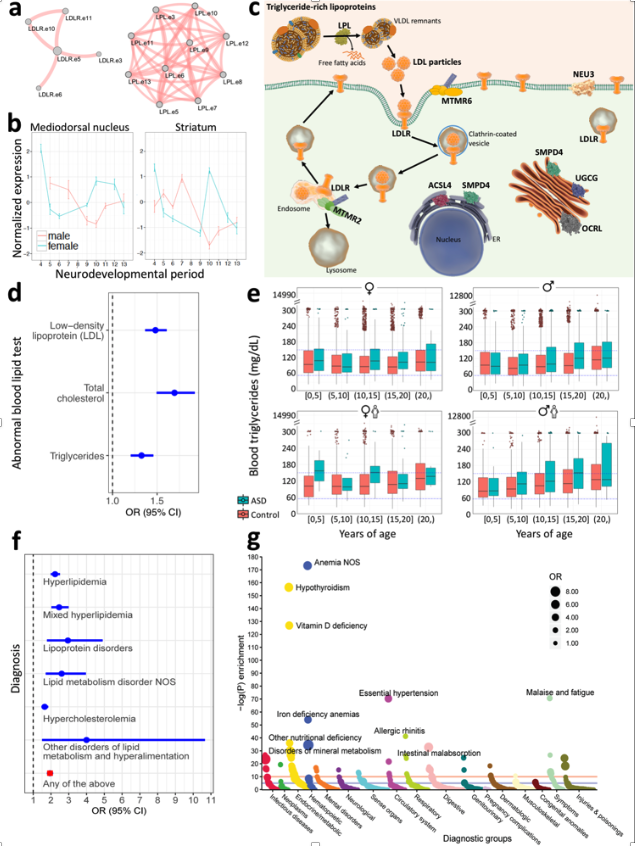
I may get into the details below, but this recent publication in Nature Medicine gives me an opportunity to revisit the problematic validity and utility of the autism diagnosis. We took a clinical insight and used it to focus on genes that had dramatically different expression patterns during the critical period of brain development. We then whittled down that collection of genes to those that bore mutations/rare variants that were found through exome sequencing in patients with autism but not those (e.g. relatives) without autism. We found four functional groups of genes that were enriched in affected individual. One of these groups—lipid metabolism—has been given short shrift, if any, in previous genetic studies. A comprehensive review of mouse models in the Jackson Laboratory revealed that many mice with a “knockout” mutation in one of the lipid metabolism genes had behavioral characteristics very similar to classical mouse models of autism. But that’s mice. We also studied tens of thousands of individual humans with autism through their electronic health record or through their claims data. Even after correcting for treatments that might affect lipid metabolism we found a substantial increased prevalence of dyslipidemia in patients with autism relative to controls. Compared to unaffected siblings, the odds ratio was approximately 1.5 (150%). More studies, as usual, will be required to confirm this dyslipidemia-autism hypothesis but the question is raised should these individuals with dyslipidemia have the same diagnosis as those patients with autism and with, for example, a immune signalling disorder?
Figure: Convergence of Autism-segregating deleterious genetic varants on lipid regulation functions, clinically reflected by an association between altered lipid profiles and autism, as well as enrichment of dyslipidemia diagnoses in individuals with autism (see publication for full description).
As late as the 18th century, a diagnosis of dropsy was a diagnosis that reputable clinicians could make without embarrassment. This diagnosis of the abnormal accumulation of fluid only gave way to diagnoses of heart failure, liver failure or kidney failure causing fluid accumulation in the 19th century. By the end of the 20th century making a diagnosis of heart failure without distinguishing whether it was due to valvular disease, ischemic heart disease, genetically inherited myopathy or another dozen causes would raise eyebrows. Not only because it would be ignorant but because these different causes have differing natural histories and most importantly, differing optimal treatments. In that perspective the diagnosis of heart failure only informs us of a shared set of findings (e.g. symptoms, clinical measurements) which do not distinguish between the various causes nor provides and disease-specific guidance for prognosis or treatment. As we reveal mechanistically distinct causes of autism, many but not all genetic, we’ve seen the definition of groups of patients who have little in common other than the DSM criteria for autism. As we’ve shown, autism is clinically manifested in far more diverse ways than would be suggested by DSM. Just by studying electronic health record data we can distinguish subgroups of individuals who, in addition to the DSM definition, have epilepsy, immunological disorders (e.g. inflammatory bowel disease, type 1 diabetes mellitus, infections) or psychiatric disorders.
There is an obvious value to the diagnosis of autism that I’ve omitted. A sociopolitical one. All the diseases that have in common autistic findings collectively have prevalence of over 1%. That puts autism somewhere between the incidence of type 1 diabetes and skin melanoma cancer in Americans, each of which have benefited from appropriate and considerable private and public attention and support. The high collective prevalence of diseases with clinical manifestations of autism, regardless of other findings, has enabled important changes such as school support programs, massively increased research funding over the past two decades and progress in screening programs. At the same time, this lumping of different causes and clinical courses, just as for the example of heart failure, does create confusion among clinicians and researchers. It also causes hurt and acrimony for patients and their families which rapidly acquires political overtones as narrated by this NPR program.
“[in a] conversation between Ari Ne’eman, who is a very, very prominent and successful activist for the concept of neurodiversity. And Ari Ne’eman, whom we have a lot of respect for, has been very, very successful in promulgating the idea that people with autism should be accepted as they are. And he had a conversation with a mother named Liz Bell. Liz Bell is the mother of a young man named Tyler. In his mom’s opinion, Tyler’s experience of autism is very, very limiting in his life and his ability to dress himself, to shave himself, to feed himself, to go out the front door by himself and not run into traffic. And these are two very, very different views of what autism represents that come down to the fact that the spectrum is so broad that there is room for an Ari Ne’eman on it and there is room for a Tyler Bell on it. And the basic disagreement between them is whether autism is something that should be cured — whether the traits that limit Tyler’s ability to be independent in life should be treated to make those traits go away. On one side, Ari is saying that it’s suppressing who he actually is and his identity; on the other side is Tyler’s mother saying that to treat him, and even cure him, of his autism would be to liberate who he is.”
Similarly, in research studies there is a point at which lumping all the different disorders is less helpful than splitting them apart. Just as for heart failure in the 21st century, realizing there are different underlying diseases allows advances in diagnostic accuracy but also in therapeutic efficacy. In the Undiagnosed Disease Network, we’ve shown again and again that more detailed clinical characterizations (aka deep phenotyping) are at least as important as whole genome sequencing in arriving at a diagnosis for these patients on long and difficulty diagnostic journeys. Several of the patients seen in the Undiagnosed Disease Network had findings fully consistent with autism in addition to other findings that led to the investigations that discovered a new disease.
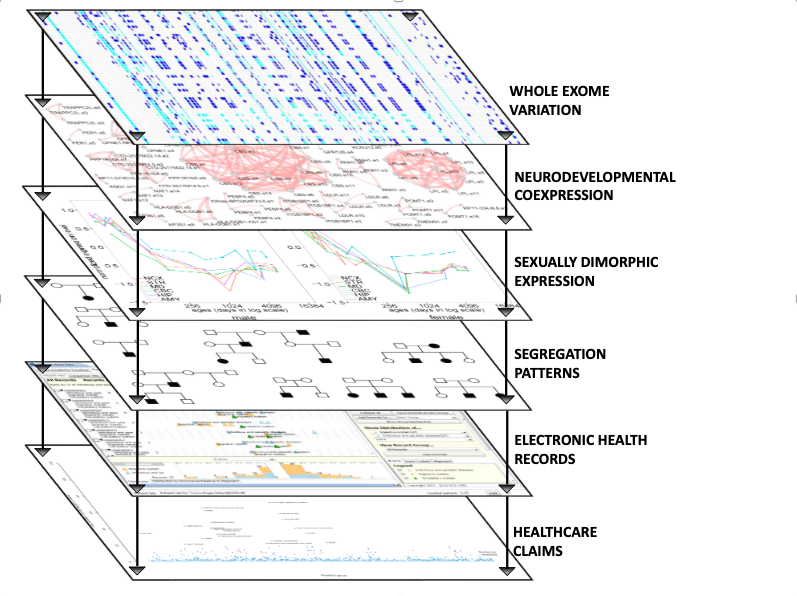
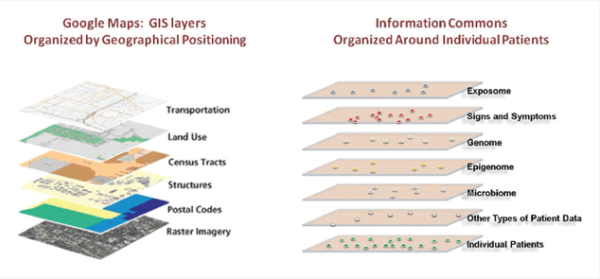
I could easily go on for thousands of words about the challenge and opportunity for modern diagnostic approaches. I’ll forestall the temptation by referring to a National Academy of Sciences report on Precision Medicine that I had the privilege to contribute to. This report was often misunderstood as arguing for molecular, genome scale characterizations of disease. This was only true in part and missed the central contention. Our argument was that by examining groups of patients and finding what they had in common using multiple data modalities (see the figure from the report, below) clinical, environmental monitoring, epigenetic, microbiome, we acquired more relevant, scientifically and clinically, diagnostic perspectives.
This multiaxial perspective of diagnosis influenced the direction of our investigation as intentionally styled in this diagram from the supplementary figures in the publication, below.
These findings of a subgroup of patients with autism who have dyslipidemia are of course just the beginning of a set of follow-on investigations. As in much of science, a useful investigation poses more questions than it answers, How does a disorder of lipid metabolism during neurodevelopment cause pathophysiologies that include findings of autism? Would early detection help treatment? Would normalization of lipid metabolism during neurodevelopment affect the course of disease? Which specific perturbations of lipid metabolism have the largest impact on neurodevelopment? These are questions which could not be posed with an overly rigid and monolithic definition of autism. Now, with the multiaxial approach of precision medicine, many more such questions can be asked and investigated.
At first, I waited for others in the government, industry and in academia to put together the data and the analyses that would allow clinicians to practice medicine that has worked the best: knowing what to expect when treating a patient. With the first COVID19 patients, ignorance was to be expected but with hundreds of patients seen early on in Europe, we could expect solid data about the clinical course of these patients. Knowing what to expect would allow doctors and nurses to be on the look out for different turns in the trajectory of their patients and thereby act rapidly and without having to wait for a full morbid declaration of yet another manifestation of viral infection pathology. Eventually we could learn what works and what does not but first just knowing what to expect would be very helpful. I’m a “cup half-full” optimist but when, in March, I saw that there were dozens of efforts that would yield important results but in months rather than weeks [If there’s interest, I can post an explanation of why I came to that conclusion], I decided that I would try to see if I could do something useful with my colleagues in biomedical informatics. Here I’ll focus on what I have found amazing—that groups can work together on highly technical tasks to complete multi-institutional analyses in less than a handful of weeks if they have shared tools, whether open source or proprietary but most importantly, if they have detailed understanding of the data from their specific home institution.
I first reached out to my i2b2 colleagues with a quick email. What are “i2b2 colleagues”? Over 15 years ago, I helped start a NIH-funded national center for biocomputing predicated on the assumption that by instrumenting the healthcare enterprise we could use the data acquired during the course of healthcare (at considerable financial cost and grueling effort of the healthcare workforce, but that’s another story). One of our software products was a free and open source software system called i2b2 (named after our NIH-funded national center for biomedical computing: Informatics for Integrating Biology and the Bedside) that enable data to be extracted by authorized users from various proprietary electronic health record systems—EHR. i2b2 was adopted by hundreds of academic health centers and an international community of informaticians work together to share knowledge (eg. how to analyze EHR data) was formed. The group meets twice a year, once in the US and once in Europe and has a non-profit foundation to keep it organized. This is the “i2b2” group I sent an email out to. I wrote that there was an opportunity to rapidly contribute to our understanding of the clinical course. We were going to have to focus on the data that was available now, was useful in the aggregate (obtaining permission to share individual patient data across institutions let alone countries is a challenging and lengthy process). As most of us were using the same software to extract data from the health record, we had a head start but we all knew there would be a lot of thought and work required to succeed. Among the many tasks we had to address:
Make sure that the labs reported by each hospital were the same ones. A glucose result can be recorded under dozens of different names in an EHR. Which one(s) should be picked? Which standard vocabulary should be used to name that glucose and other labs (also known as the terrifyingly innocuous-sounding yet soul-deadening process of “data harmonization.”
Determine what constitutes a COVID19 patient? In some hospitals they received patients said to be COVID19 positive but they don’t know positive by which test. In others they use two specific tests. If the first is negative and the second is positive is the time of diagnosis: the admission, the time of the first test or second test?
Assigning these tasks across more than 100 collaborators in 5 countries during the COVID19 mandatory confinement and then coordinating these without a program manager was going to be challenging under any conditions. Doing so with the goal of showing results within weeks, even moreso. In addition to human resourcefulness and passion we were fortunate to have a few tools that made this complex international process a tractable one. These were Slack, Zoom, Google documents, Jupyter notebooks, Github and a shared workspace on the Amazon cloud (where the aggregate data was stored, the individual patient data remained at all the hospital sites). We divided the tasks into subtasks (e.g. common data format, visualization, results website, manuscript writing, data analysis) and created a Slack channel for each. Then those willing to work on the subtask self-organized on each of their respective channels. Three out of the five tools I’ve listed above were not available just 10 years ago.
We were able to publish the first results and a graphically sophisticated website within 4 weeks. See covidclinical.net for the result. That and pre-print. All of this with consumer-level tools and of course a large prior investment in open source software designed for the analysis of electronic health records. Now we have a polished version of the pre-print published in Nature Digital Medicine and a nice editorial.
Nonetheless, the most important takeaway from this rapid and successful sprint to characterize the clinical course of COVID19 is the familiarity each of the informaticians at each clinical site had with their institutional data. This certainly did help them respond rapidly to data requests but that was less important than understanding precisely the semantics of their own data. Even sites that would have the same electronic health record vendor would have practice styles that would mean that a laboratory name (e.g. Troponin) in one clinic would not be the same test as in the ICU laboratory. Sorting that out in multiple Zoom and Slack conversations required dozens of conversations. Yet, many of the commercial aggregation efforts are of necessity blind to these distinctions because their business model precludes this detailed back and forth with each source of clinical data. Academic aggregation efforts tend to be more fastidious about aligning semantics across sites but it’s understandable that the committee-driven processes that result are ponderous and with hundreds of hospitals take months, at least. Among the techniques we used to maintain our agility was a ruthless focus on a subset of the data for a defined set of questions and to steadfastly refuse to expand our scope until we completed the first, narrowly defined tasks, as encapsulated by our first pre-print. Our experience with international colleagues using i2b2 since 2006 also created a lingua franca and patience with reciprocal analytic “favor-asking.” 4CE has continued to have multiple meetings per week and I hope to add to this narrative in the near future.